
As I was doing research into various methods for managing data quality, I stumbled upon a great use case that applied Machine learning to a very real problem plaguing many organizations who want to scale their data businesses, especially in the age of AI. The article, “Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform“, discusses how Netflix transitioned from a static rule-based system (Pensive) to an ML-assisted one (Nightingale) which helped to solve its immediate scaling pain points.
I want to discuss how the methods applied could be further enhanced with Multi-agent remediation through an improved “gate-keeper” and integrated data quality checks.
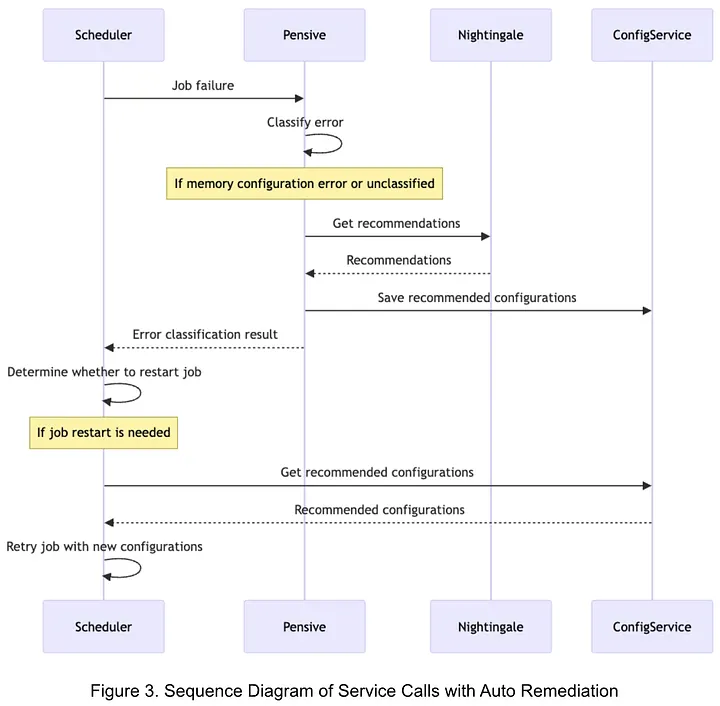
While Netflix’s shift from a purely rule-based classification engine to an ML-powered optimizer is a massive leap forward for operational efficiency, I believe it represents a specific “point in time” in the evolution of DataOps. The current architecture still relies on several rigid assumptions that leave room for iteration. In my day-to-day as a Senior Data Consultant, I constantly see organizations mask upstream data pipeline decay by treating the infrastructure symptoms rather than the root data diseases.
Here is my take on the fundamental flaws of the current approach and how we can push the boundaries further to build truly resilient data platforms.
1) The “Gatekeeper” Flaw: Over-Reliance on Static Rules
In the Netflix architecture, the rule-based classifier still acts as the initial gatekeeper. The ML service is only invoked if a log matches a predefined regex rule for known memory errors or “unclassified” errors.
This creates a massive blind spot. Static rules inherently decay as the underlying data platform evolves. If a complex, compounding error is misclassified by a stale regex rule, the ML service is bypassed entirely, and the system fails silently or retries inefficiently.
- My Recommendation: Add a ML model to supersede the rule-based engine, or at least operate concurrently. An anomaly detection model could continuously evaluate all pipeline failures in the background to flag misclassifications by the rule-based engine. This would create an automated feedback loop that updates the static “gate-keeper” without requiring manual engineering effort for every new edge case.
2) Treating Symptoms, Not Diseases: The Need for Integrated Data Quality Checks
The current optimizer explores Spark configuration parameters (like spark.executor.memory) that were pre-selected by domain experts. It assumes the root cause of an error is purely an infrastructure configuration issue. However, anyone who has spent time building data quality scorecards knows that an Out-Of-Memory (OOM) error is frequently just a symptom of an underlying data quality issue. Sudden data skew, null value explosions, or duplicate records flooding a join will crash a Spark job just as quickly as a bad memory config. Simply allocating more memory to a job processing bad data is like putting a band-aid on a bullet wound—it costs the business money and doesn’t fix the actual problem.
- My Recommendation: The feature vector fed into the prediction model must be expanded to include data quality metrics and metadata. Users should first determine acceptable thresholds (baseline) for automatic compute resource increases and meticulously track these resource trends over time. Establishing these baselines helps differentiate between genuine data quality issues—like sudden data skew or volume explosions—and simple configuration drift. If a failing job suddenly requires memory well beyond the acceptable historical threshold, the recommendation shouldn’t be to blindly “increase memory”; it should be to halt the pipeline and flag the upstream data source for investigation. Integrating these operational thresholds directly into the remediation logic ensures we aren’t paying premium cloud compute costs just to process garbage data.
3) The Rise of Multi-Agent Remediation
Currently, the solution relies on a monolithic predictive model (a two-headed Multilayer Perceptron) to guess the probability of success and the compute cost. But as data platforms grow exponentially more complex, a single predictive model struggles to account for diverse, intersecting failure modes spanning network latency, data quality, and compute scaling.
- My Recommendation: Transitioning to a Multi-Agent System (MAS) would be a highly effective next step. Instead of one model making a blanket prediction, organizations could deploy specialized, autonomous agents.
- An Orchestrator Agent to manage the following agents and retries
- A Data Evaluation Agent to evaluate schema changes, volume spikes, and data skew
- An Infrastructure Agent to evaluate cluster health and Spark configurations
- A Code Profiling Agent to identify poorly optimized SQL or PySpark logic
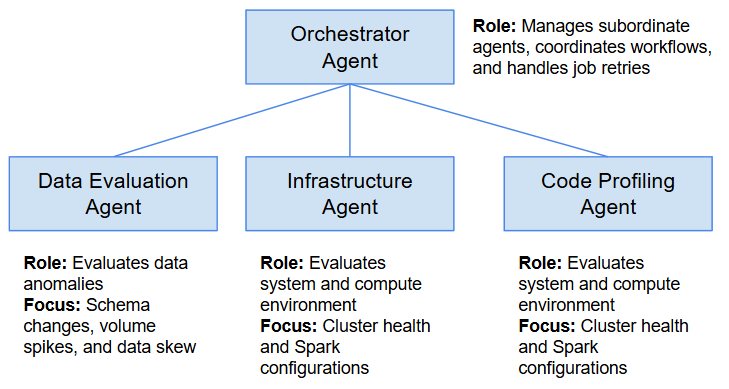
When a job fails, the Manager Agent delegates the investigation. The specialized agents then negotiate the best holistic remediation strategy. For example, the Infrastructure Agent might request more memory to resolve an OOM error, but the Data Diagnosis Agent could veto the request because it identified that the source data is corrupted and needs to be quarantined first.
Conclusion
Netflix’s Auto Remediation is an impressive engineering feat that significantly reduces operational burden and cloud costs. But as we look toward the future of data platforms, simply automating the retry of a failed job isn’t enough. By implementing dynamic ML gate-keepers, integrating upstream data quality checks, and embracing multi-agent orchestration, we can shift from reactive infrastructure patching to true, intelligent pipeline resilience. Agree? Disagree? I welcome any feedback or discussions, feel free to leave me a comment or contact me directly!